diffusion model
采样-ddpm
神经网络尝试在每一步都完整预测噪点
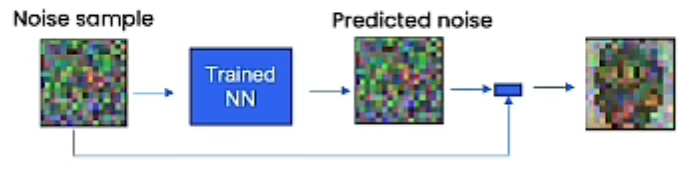
对于预测到的噪点,我们使用原有的噪点图减去预测的噪点图,就会获得一个稍微清晰一点的图片。但是它并没有完全去除所有的噪点,所以需要很多步迭代才能获得较高质量的采样。
但是这种的神经网络需要类似这种正态分布的噪点样本作为输入,所以在每一次迭代需要加入额外的噪点。这样有利于稳定神经网络算法来区分接近数据集的平均值的样本。意思是,如果不加相应的噪点,nn只会生成相似的样本。
diffusion model的nn被称为UNet
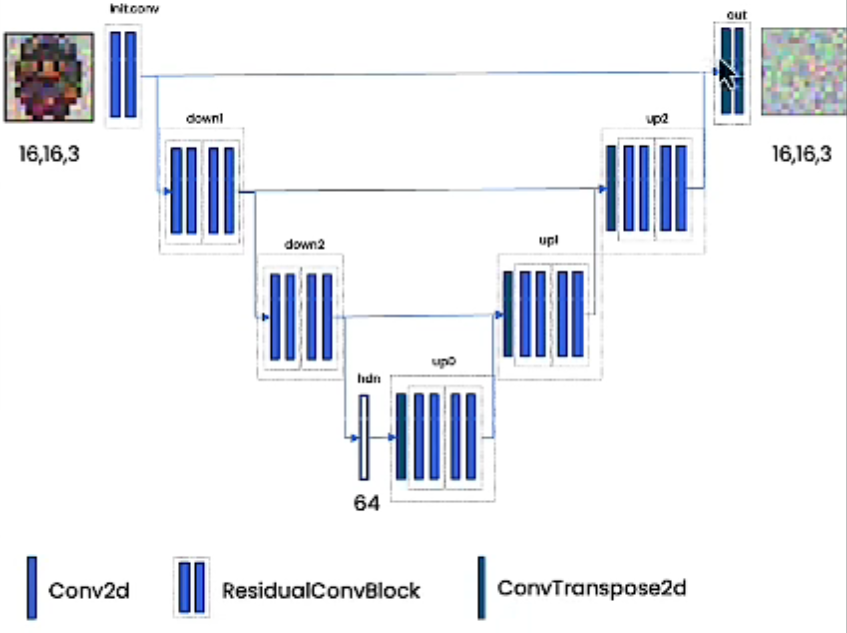
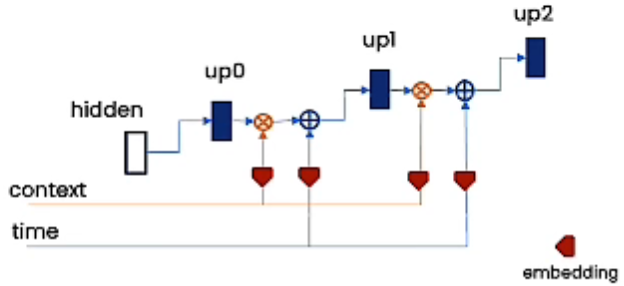
UNet可以嵌入更多的信息,包括时间信息,上下文信息。
训练
对样本加个噪点,然后让nn去算,然后相减,计算出loss,然后反向传播
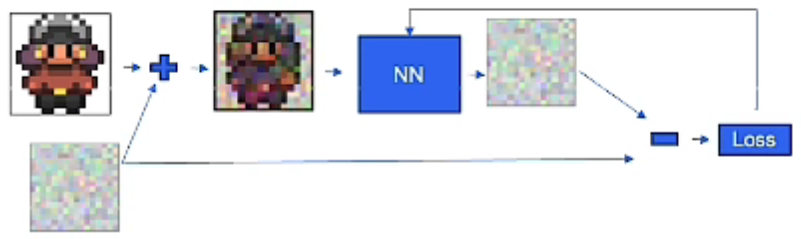
为了让训练更加稳定,对每个样本选择随机的时间信息(迭代次数)。
控制样本
通过嵌入上下文来控制训练模型。
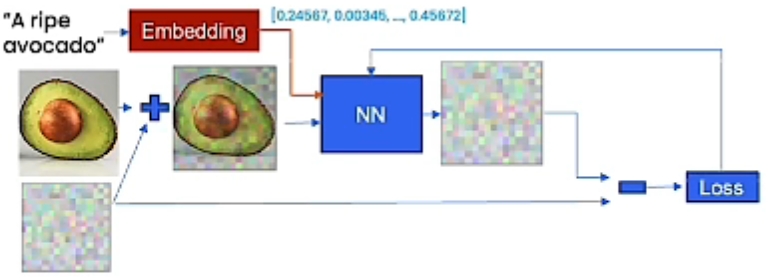
比如你有一张牛油果的图片,然后有一句话”一颗成熟的牛油果“,然后你可以将加噪点的图片和这句话一同放入nn进行训练。
此时你有一个椅子的模型,就可以预测一个牛油果椅子。

上下文是一个可以控制生成的向量,可以是一句话,也可以是几个简短的关键字。
加速采样–ddim
传统的采样需要很多时间步长(timestep)
denoising diffusion implicit models
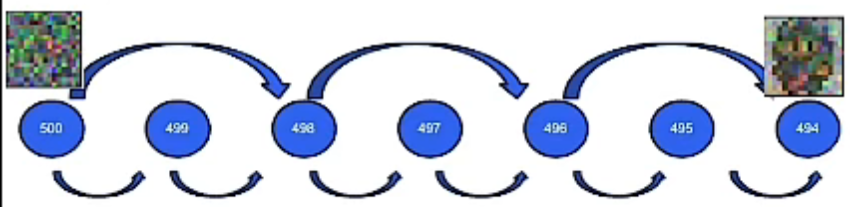
ddim可以跳过时间步长,因为它打破了马尔卡夫假设。
它的本质是预测一个最终输出的粗略草图,然后通过去噪过程对其进行优化。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.

Recent Post