Machine Learning Algorithms A Review
摘要
机器学习 (ML) 是对计算机系统用于执行特定任务而无需显式编程的算法和统计模型的科学研究。我们日常使用的许多应用程序中的学习算法。每次使用像谷歌这样的网络搜索引擎来搜索互联网时,其如此有效的原因之一是因为学习算法已经学会了如何对网页进行排名。这些算法用于各种目的,例如数据挖掘、图像处理、预测分析等。使用机器学习的主要优点是,一旦算法学会如何处理数据,它就可以自动完成其工作。本文对机器学习算法的广泛应用进行了简要回顾和未来展望。
算法分类
- supervised learning
- decision tree
- naive bayes
- support vector machine
- unsupervised learning
- principal component analysis
- k-means
- semi-supervised learning
- generative model
- self training
- transductive support vector machine
- reinforcement learning
- multi-task learning
- ensemble learning
- boosting
- bagging
- neutral network
- supervised neural network
- unsupervised neural network
- reinforce neural network
- instance based learning
- k-nearest neighbor
决策树(decision tree)
决策树是以树的形式表示选择及其结果的图。图中的节点表示事件或选择,图的边表示决策规则或条件。每棵树都由节点和分支组成。每个节点代表要分类的组中的属性,每个分支代表该节点可以取的值。
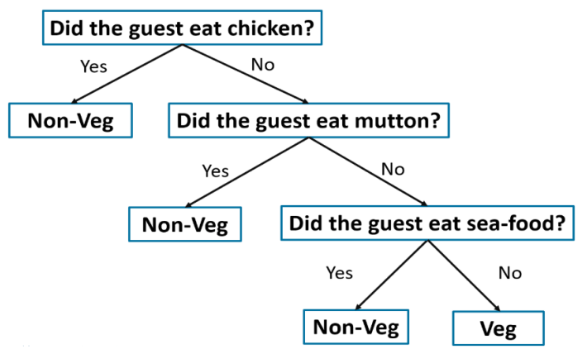
决策树的实现伪代码如下
1 | def decisionTreeLearning(examples, attributes, parent_examples): |
朴素贝叶斯(naive bayes)
它是一种基于贝叶斯定理的分类技术,假设预测变量之间独立。简而言之,朴素贝叶斯分类器假设类中特定特征的存在与任何其他特征的存在无关。朴素贝叶斯主要针对文本分类行业。它主要用于依赖于发生的条件概率的聚类和分类目的。
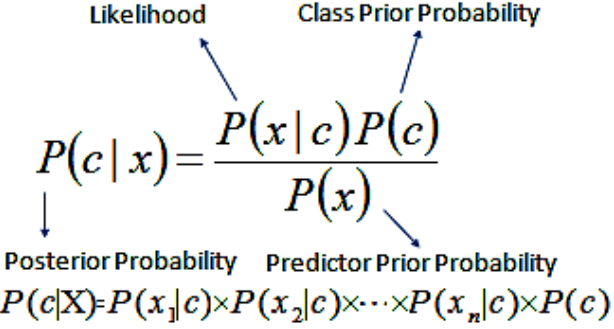
伪代码如下:
输入:训练数据集T,
F= (f1, f2, f3,.., fn) // 测试数据集中预测变量的值。
输出:一类测试数据集。
步骤:
- 读取训练数据集T;
- 计算每类预测变量的均值和标准差;
- 重复计算每类中使用高斯密度方程计算fi的概率;直到计算出所有预测变量(f1、f2、f3、..、fn)的概率。
- 计算每个类别的可能性;
- 获得最大的可能性
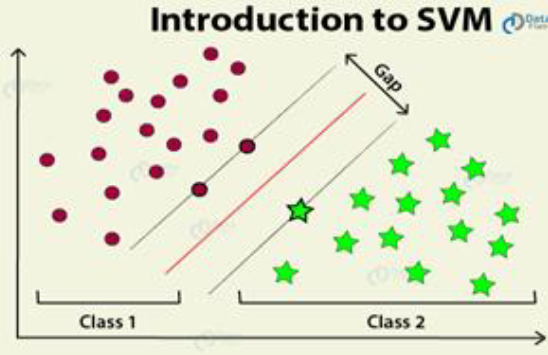
支持向量机(support vector machine)
另一种最广泛使用的最先进的机器学习技术是支持向量机(SVM)。在机器学习中,支持向量机是具有相关学习算法的监督学习模型,用于分析用于分类和回归分析的数据。除了执行线性分类之外,SVM 还可以使用所谓的核技巧有效地执行非线性分类,将其输入隐式映射到高维特征空间。它基本上是在类之间绘制边距。边距的绘制方式使得边距与类别之间的距离最大,从而最大限度地减少分类误差。
伪代码如下:
1 | 初始化 Yi = YI for i ⋹ I |
主成分分析(Principal Component Analysis)
主成分分析是一种统计过程,它使用正交变换将一组可能相关变量的观测值转换为一组称为主成分的线性不相关变量的值。在这种情况下,数据的维度被减少,使得计算更快更容易。它用于通过线性组合来解释一组变量的方差-协方差结构。它经常被用作降维技术。
K 均值聚类(k-means)
K-means 是解决众所周知的聚类问题的最简单的无监督学习算法之一。该过程遵循一种简单易行的方法,通过一定数量的聚类对给定数据集进行分类。主要思想是定义 k 个中心,每个簇一个。这些中心应该巧妙地放置,因为不同的位置会导致不同的结果。因此,更好的选择是将它们放置得尽可能远离彼此。
这篇文章没有什么意义,主要是介绍,很多内容直接抄的,连字都懒得打,直接截图。
避雷Batta Mahesh,这个人的其它文章中还提到了制造永动机。
